Visium HD ONT (isoform)#
This notebook demonstrates essential steps for analyzing spatial isoform usage using Visium HD with long-read (ONT) sequencing data:
Load preprocessed transcript-level quantification.
Run FFT-accelerated spatial variability tests with
SplisosmFFT.Compare results across spatial resolutions and with
SplisosmNP.
For differential usage testing with SplisosmFFT, see the Visium HD FFPE (probe) Part II tutorial.
Estimated runtime: ~5 min.
Preliminary notes#
In this tutorial, we use a Visium HD 3’ adult mouse brain (fresh frozen) data sequenced with Oxford Nanopore. For dataset access and workflow details, please check the official release page from EPI2ME.
Specifically, we downloaded the following outputs from the EPI2ME page:
- spaceranger/hac/HD_Adult_Mouse_Brain/
# Space Ranger outputs (`possorted_genome_bam.bam` is not required).
- wf-single-cell/sup/SAMPLE_S1_L001/SAMPLE_S1_L001.transcript_raw_feature_bc_matrix_2um/
# transcript-level count matrix (generated by EPI2ME with a custom pipeline).
- wf-single-cell/sup/SAMPLE_S1_L001/SAMPLE_S1_L001.transcriptome.gff.gz
# GFF transcript annotation file.
We then ran convert_mtx_to_h5.py (available under the scripts directory) to prepare a barcode-by-transcript count matrix raw_tx_bc_matrix.h5, keeping only reference isoforms.
python convert_mtx_to_h5.py \
'./wf-single-cell/sup/SAMPLE_S1_L001/SAMPLE_S1_L001.transcript_raw_feature_bc_matrix_2um' \
'./wf-single-cell/sup/SAMPLE_S1_L001/SAMPLE_S1_L001.transcriptome.gff.gz' \
'raw_tx_bc_matrix.h5'
Imports#
from __future__ import annotations
import gzip
import re
import warnings
from pathlib import Path
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import spearmanr
import spatialdata as sd
import spatialdata_plot
from spatialdata import rasterize_bins
from splisosm import SplisosmFFT, SplisosmNP
from splisosm.utils import counts_to_ratios
warnings.filterwarnings("ignore", category=FutureWarning)
plt.rcParams["figure.dpi"] = 120
plt.rcParams["figure.figsize"] = (6, 4)
Configure paths and core parameters#
# Input data (provided by user)
sdata_zarr = Path("/path/to/sdata_tx.filtered.zarr")
gff_file = Path("/path/to/SAMPLE_S1_L001.transcriptome.gff.gz")
# Resolution for primary testing
dataset_id = ""
test_table = "square_016um"
test_bins_element = f"{dataset_id}_{test_table}"
# Feature grouping and quality filters
group_iso_candidates = ["gene_ids", "gene_id"]
gene_name_candidates = ["gene_name", "gene_symbol", "gene_names"]
ONT data is generally more sparse than short-read data. To test as many genes as possible, we use a more lenient min_bin_pct threshold (the minimum percentage of non-zero bins required to keep an isoform).
# Isoform and gene filtering thresholds
min_counts = 10
min_bin_pct = 0.001 # a more lenient filter for sparse ONT data
Load preprocessed transcript-level SpatialData#
We load the preprocessed SpatialData object generated by load_visiumhd_probe with raw_tx_bc_matrix.h5 as inputs.
%%time
if not sdata_zarr.exists():
# from splisosm.io import load_visiumhd_probe
# sdata = load_visiumhd_probe(
# path="./spaceranger/hac/HD_Adult_Mouse_Brain",
# bin_sizes=[2, 8, 16],
# filtered_counts_file=True,
# path_to_feature_2um_h5="raw_tx_bc_matrix.h5",
# )
# sdata.write_zarr("sdata_tx.filtered.zarr")
raise FileNotFoundError(f"Cannot find Zarr store: {sdata_zarr}")
if not gff_file.exists():
raise FileNotFoundError(f"Cannot find GFF file: {gff_file}")
print("Loading preprocessed SpatialData...")
sdata = sd.read_zarr(sdata_zarr)
sdata
Loading preprocessed SpatialData...
CPU times: user 7.06 s, sys: 1.09 s, total: 8.15 s
Wall time: 5.94 s
SpatialData object, with associated Zarr store: /Users/jysumac/Projects/SPLISOSM_paper/data/visiumhd_ont_mouse_cbs/sdata_tx.filtered.zarr
├── Images
│ ├── '_hires_image': DataArray[cyx] (3, 3000, 3200)
│ └── '_lowres_image': DataArray[cyx] (3, 563, 600)
├── Shapes
│ ├── '_square_002um': GeoDataFrame shape: (7857218, 1) (2D shapes)
│ ├── '_square_008um': GeoDataFrame shape: (492663, 1) (2D shapes)
│ └── '_square_016um': GeoDataFrame shape: (123658, 1) (2D shapes)
└── Tables
├── 'square_002um': AnnData (7857218, 48001)
├── 'square_008um': AnnData (492663, 48001)
└── 'square_016um': AnnData (123658, 48001)
with coordinate systems:
▸ '', with elements:
_hires_image (Images), _lowres_image (Images), _square_002um (Shapes), _square_008um (Shapes), _square_016um (Shapes)
▸ '_downscaled_hires', with elements:
_hires_image (Images), _square_002um (Shapes), _square_008um (Shapes), _square_016um (Shapes)
▸ '_downscaled_lowres', with elements:
_lowres_image (Images), _square_002um (Shapes), _square_008um (Shapes), _square_016um (Shapes)
Note that cell-segmentation results are not available for this dataset.
def pick_first(columns, candidates):
for c in candidates:
if c in columns:
return c
return None
print("Tables:", sorted(sdata.tables.keys()))
print("Images:", sorted(getattr(sdata, "images", {}).keys()))
print("Shapes:", sorted(getattr(sdata, "shapes", {}).keys()))
if test_table not in sdata.tables:
raise ValueError(f"{test_table} is not available. Choose from: {sorted(sdata.tables.keys())}")
adata_test = sdata.tables[test_table]
group_iso_by = pick_first(adata_test.var.columns, group_iso_candidates)
if group_iso_by is None:
raise ValueError(
"Could not infer grouping column for transcript features. "
f"Available var columns: {list(adata_test.var.columns)}"
)
gene_name_col = pick_first(adata_test.var.columns, gene_name_candidates) or group_iso_by
if test_bins_element not in getattr(sdata, "shapes", {}):
test_bins_element = test_table
print(f"Using table={test_table}, bins={test_bins_element}")
print(f"Grouping column={group_iso_by}, display names={gene_name_col}")
Tables: ['square_002um', 'square_008um', 'square_016um']
Images: ['_hires_image', '_lowres_image']
Shapes: ['_square_002um', '_square_008um', '_square_016um']
Using table=square_016um, bins=_square_016um
Grouping column=gene_ids, display names=gene_name
For each isoform, we have the following metadata columns (inferred from the GFF file):
adata_test.var.head(2)
| gene_ids | probe_ids | feature_types | gene_name | genome | |
|---|---|---|---|---|---|
| ENSMUST00000000001 | ENSMUSG00000000001 | ENSMUST00000000001 | Gene Expression | Gnai3 | |
| ENSMUST00000000028 | ENSMUSG00000000028 | ENSMUST00000000028 | Gene Expression | Cdc45 |
As expected, the ONT-based data is sparser than short-read 3’ and targeted Visium HD datasets.
def summarize_table(adata):
X = adata.layers["counts"] if "counts" in adata.layers else adata.X
if hasattr(X, "nnz"):
nnz = int(X.nnz)
total = int(X.shape[0] * X.shape[1])
density = nnz / total if total else np.nan
else:
arr = np.asarray(X)
nnz = int(np.count_nonzero(arr))
total = int(arr.size)
density = nnz / total if total else np.nan
return {
"n_features": int(adata.n_vars),
"n_bins": int(adata.n_obs),
"count_mtx_density": density,
}
rows = []
for key in sorted(sdata.tables.keys()):
if key.startswith("square_"):
rows.append({"table": key, **summarize_table(sdata.tables[key])})
pd.DataFrame(rows).sort_values("table")
| table | n_features | n_bins | count_mtx_density | |
|---|---|---|---|---|
| 0 | square_002um | 48001 | 7857218 | 0.000098 |
| 1 | square_008um | 48001 | 492663 | 0.001379 |
| 2 | square_016um | 48001 | 123658 | 0.004826 |
Finally, take a look at the tissue structure and spatial distribution of a few isoforms.
def ensure_rasterized(sdata, bin_table: str, bin_element: str, layer: str = "counts"):
raster_key = f"rasterized_{bin_table}_{layer}"
if raster_key in sdata.images:
return raster_key
adata = sdata.tables[bin_table]
adata.X = adata.layers[layer] if layer in adata.layers else adata.X
if hasattr(adata.X, "tocsc") and getattr(adata.X, "format", None) != "csc":
adata.X = adata.X.tocsc()
sdata[raster_key] = rasterize_bins(
sdata,
bins=bin_element,
table_name=bin_table,
col_key="array_col",
row_key="array_row",
)
return raster_key
%%time
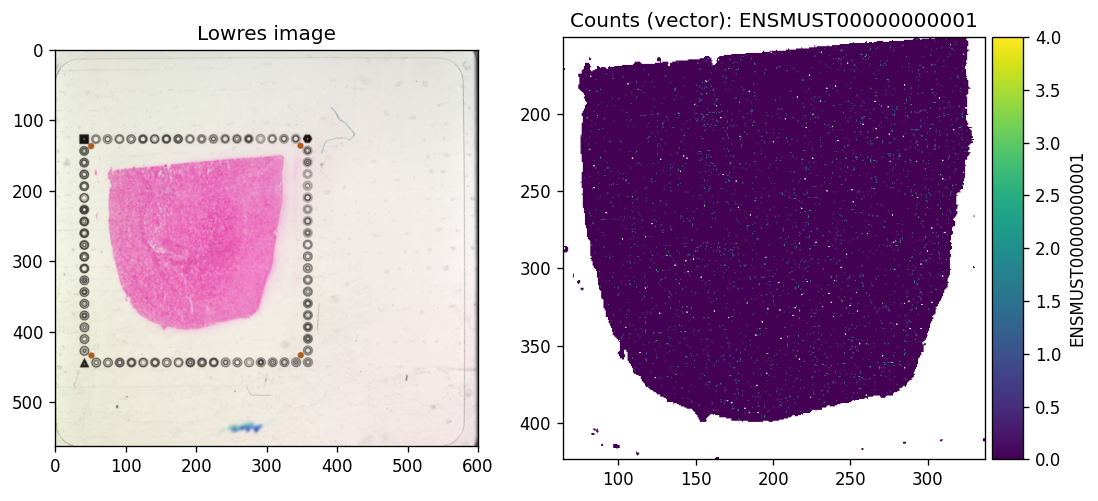
tx_name = 'ENSMUST00000000001' # Gnai3
axes = plt.subplots(1, 2, figsize=(10, 5))[1].flatten()
sdata.pl.render_images(f"{dataset_id}_lowres_image").pl.show(
coordinate_systems=f"{dataset_id}_downscaled_lowres",
ax=axes[0], title="Lowres image"
)
sdata.pl.render_shapes(f"{dataset_id}_square_016um", color=tx_name).pl.show(
coordinate_systems=f"{dataset_id}_downscaled_lowres",
ax=axes[1], title=f"Counts (vector): {tx_name}"
)
CPU times: user 6.38 s, sys: 791 ms, total: 7.17 s
Wall time: 7.32 s
Spatial variability testing with SplisosmFFT#
model = SplisosmFFT(neighbor_degree=1, rho=0.99)
model.setup_data(
sdata=sdata,
bins=test_bins_element,
table_name=test_table,
col_key="array_col",
row_key="array_row",
layer="counts",
group_iso_by=group_iso_by,
gene_names=gene_name_col,
min_counts=min_counts,
min_bin_pct=min_bin_pct,
filter_single_iso_genes=True
)
model
=== SplisosmFFT
- Number of genes: 1558
- Number of spots: 123658
- Number of spots after rasterization: 175561
- Number of covariates: 0
- Average isoforms per gene: 2.3
=== Model configurations
- Neighborhood degree: 1
- Spatial autocorrelation rho: 0.99
=== Test results
- Spatial variability: N/A
- Differential usage: N/A
While many genes have more than 10 isoforms detected, the effective number of isoforms (adjusted for expression level) is much smaller.
%%time
gene_meta = model.extract_feature_summary(level="gene")
feature_meta = model.extract_feature_summary(level="isoform")
gene_meta.sort_values("perplexity", ascending=False).head(5)
Genes: 100%|██████████| 1558/1558 [00:00<00:00, 1937.07it/s]
CPU times: user 813 ms, sys: 146 ms, total: 959 ms
Wall time: 962 ms
| n_isos | perplexity | pct_bin_on | count_avg | count_std | major_ratio_avg | |
|---|---|---|---|---|---|---|
| gene | ||||||
| Pantr1 | 9 | 7.620990 | 0.024964 | 0.032291 | 0.221045 | 0.229902 |
| Mtch1 | 8 | 7.095370 | 0.023144 | 0.029185 | 0.205137 | 0.234968 |
| Gas5 | 17 | 6.323551 | 0.111630 | 0.165667 | 0.564609 | 0.476765 |
| Egfl7 | 6 | 5.437132 | 0.014726 | 0.018689 | 0.165910 | 0.272177 |
| Paxx | 7 | 5.433822 | 0.035930 | 0.048642 | 0.276595 | 0.321363 |
Next, we run method="hsic-ir" to detect spatial variability in isoform usage.
%%time
model.test_spatial_variability(
method="hsic-ir",
ratio_transformation="none",
n_jobs=-1,
print_progress=True,
)
SV [hsic-ir]: 100%|██████████| 116/116 [00:04<00:00, 23.42it/s]
CPU times: user 24.5 s, sys: 5.28 s, total: 29.8 s
Wall time: 6.33 s
sv_res_16um = model.get_formatted_test_results(
"sv", with_gene_summary=True
).sort_values("pvalue_adj")
sv_res_16um.head(5)
| gene | statistic | pvalue | pvalue_adj | n_isos | perplexity | pct_bin_on | count_avg | count_std | major_ratio_avg | |
|---|---|---|---|---|---|---|---|---|---|---|
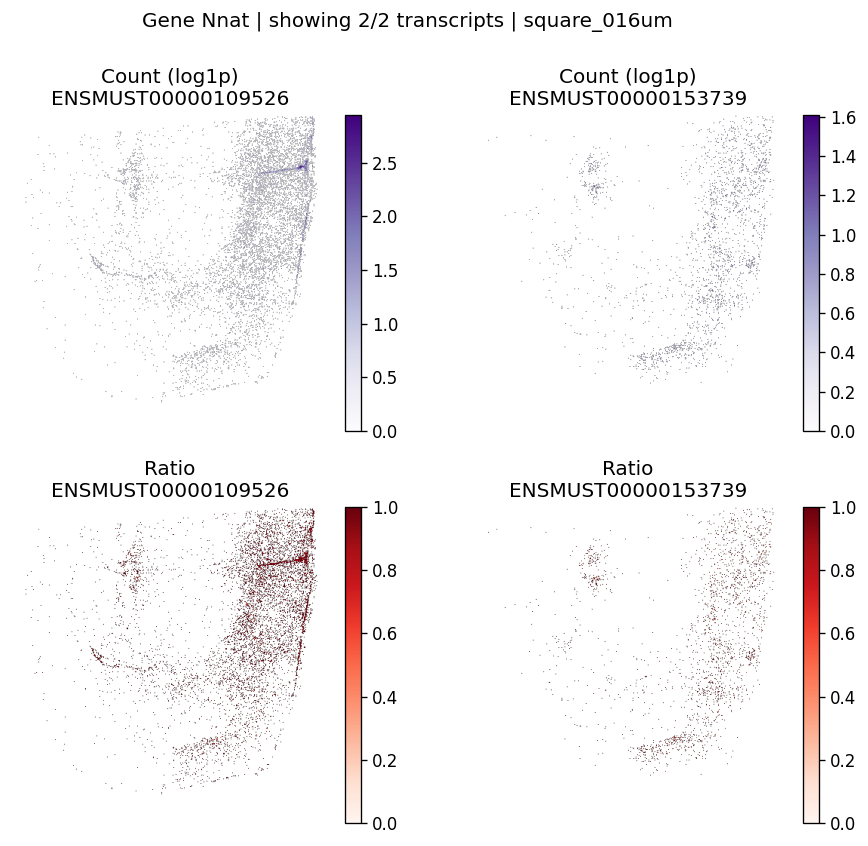
| 1133 | Nnat | 3.349203e-07 | 0.0 | 0.0 | 2 | 1.650491 | 0.073922 | 0.113628 | 0.503994 | 0.799516 |
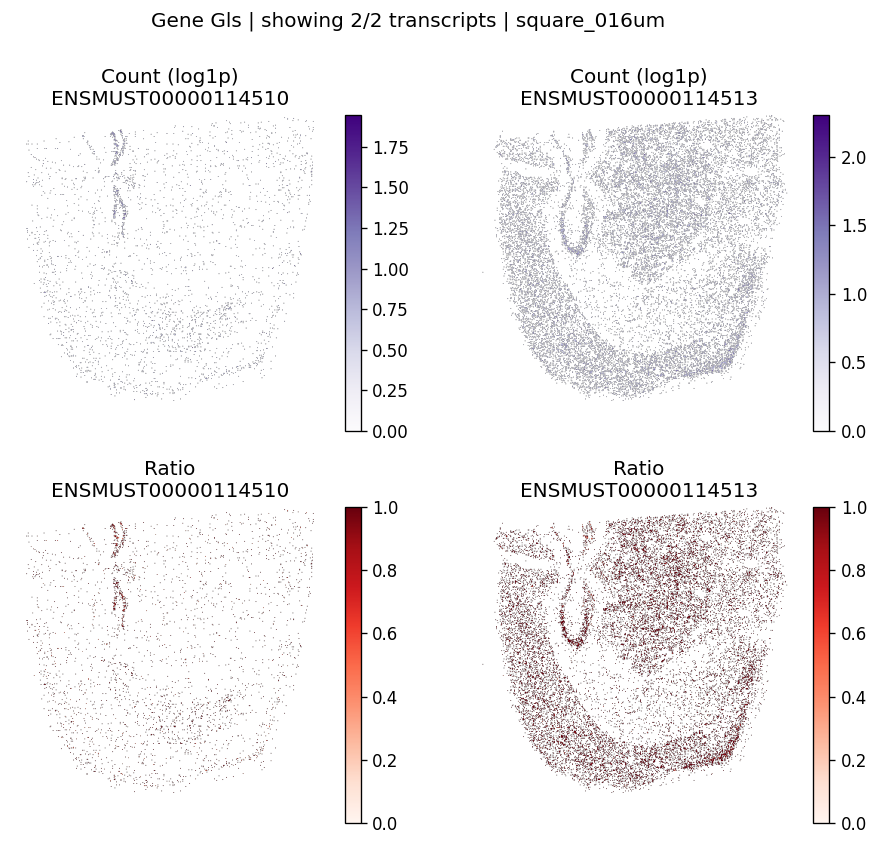
| 1356 | Gls | 6.044231e-07 | 0.0 | 0.0 | 2 | 1.460988 | 0.170721 | 0.241117 | 0.614752 | 0.873793 |
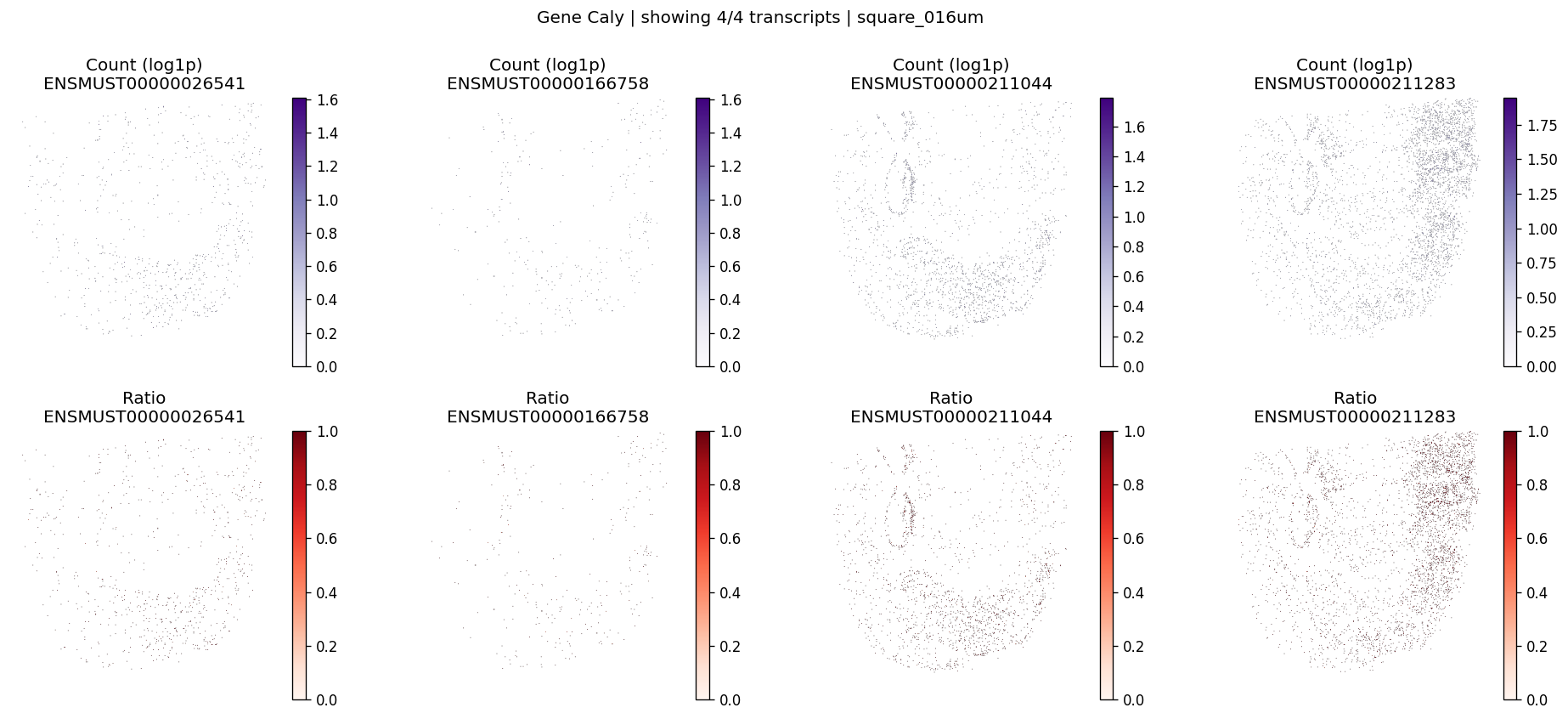
| 340 | Caly | 4.102586e-07 | 0.0 | 0.0 | 4 | 2.824695 | 0.052330 | 0.071544 | 0.337891 | 0.579632 |
| 610 | Fxyd1 | 2.116209e-07 | 0.0 | 0.0 | 5 | 3.250710 | 0.031886 | 0.043297 | 0.265310 | 0.555099 |
| 1218 | Olfm1 | 7.099970e-07 | 0.0 | 0.0 | 3 | 2.023517 | 0.177611 | 0.269962 | 0.701330 | 0.766378 |
Let’s take a look at the top significant genes and their spatial isoform usage patterns.
sig_001 = int((sv_res_16um["pvalue_adj"] < 0.01).sum())
print(
"Spatially variable genes (FDR < 0.01, 16 µm): "
f"{sig_001} out of {sv_res_16um.shape[0]} total genes"
)
top_genes = sv_res_16um.head(10)["gene"].astype(str).tolist()
top_genes[:5]
Spatially variable genes (FDR < 0.01, 16 µm): 710 out of 1558 total genes
['Nnat', 'Gls', 'Caly', 'Fxyd1', 'Olfm1']
# Visualize maps for a few significant genes
for gene_id in top_genes[:3]:
plot_gene_tx_maps(
sdata=sdata,
bin_table=test_table,
bin_element=test_bins_element,
gene_id=gene_id,
tx_meta=feature_meta,
group_col='gene_name',
max_peaks=6,
hide_zero_ratio=True,
)
%%time
# Plot an example gene of interest
plot_gene_tx_maps(
sdata=sdata,
bin_table=test_table,
bin_element=test_bins_element,
gene_id='Myl6',
tx_meta=feature_meta,
group_col='gene_name',
max_peaks=6,
hide_zero_ratio=True,
)
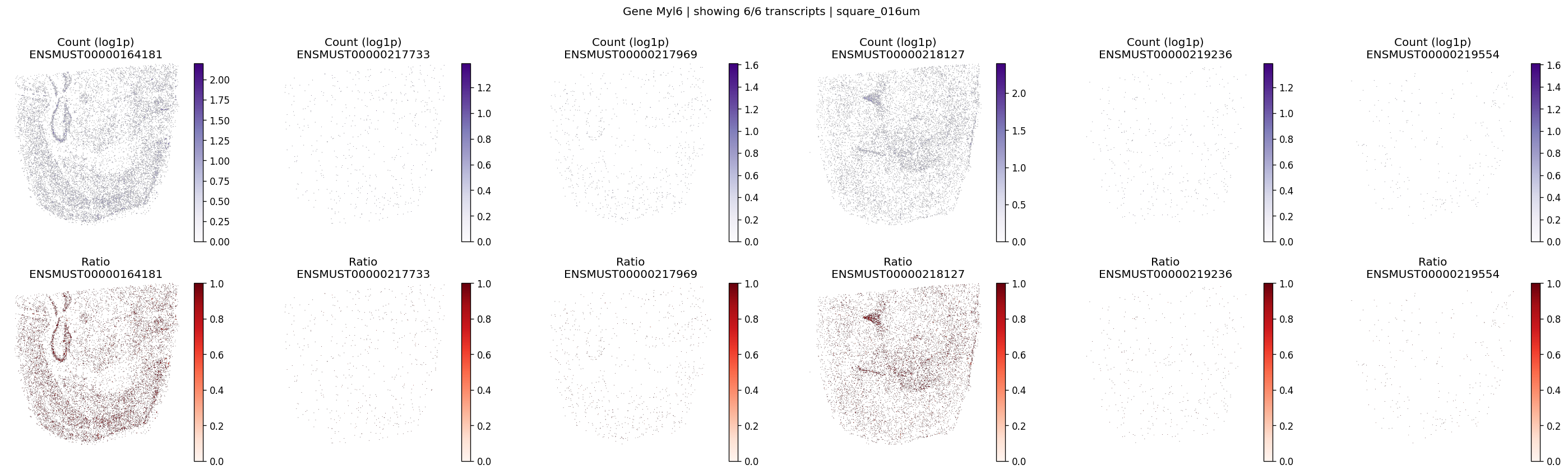
CPU times: user 401 ms, sys: 40.9 ms, total: 442 ms
Wall time: 445 ms
And the transcript structure of a gene (showing kept isoforms after filtering):
%%time
# Plot an example gene of interest with transcript structures
plot_feature_transcript_structure(
sdata=sdata,
bin_table=test_table,
gene_id="Myl6",
feature_meta=feature_meta,
group_col="gene_name",
gff_path=gff_file,
top_k=10,
)
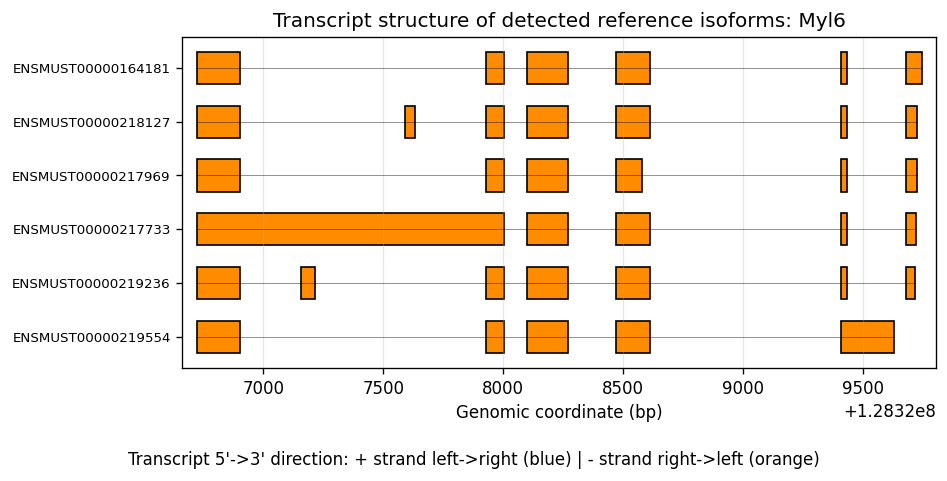
CPU times: user 2.84 s, sys: 51.6 ms, total: 2.89 s
Wall time: 2.9 s
Method comparison: SplisosmFFT vs SplisosmNP#
We now compare FFT-accelerated and non-parametric spatial variability tests at 16 µm resolution.
Note: Since v1.2.0, SplisosmNP SV tests use Liu’s approximation from full-rank spatial-kernel cumulants by default. See the SV hyperparameter optimization notebook for comparison with the legacy low-rank approach.
For large implicit CAR kernels, null_configs={"n_probes": m} controls the Hutchinson trace budget. Smaller m is faster but noisier. To emphasize broad smooth patterns, prefer increasing rho (for example, rho=0.999) rather than rank truncation.
%%time
# Run SplisosmNP at 16µm for direct comparison with SplisosmFFT
model_np = SplisosmNP(
k_neighbors=4,
rho=0.99,
standardize_cov=False # faster
)
model_np.setup_data(
adata=sdata.tables[test_table],
spatial_key='spatial', # adata.obsm key for spatial coordinates
layer='counts',
group_iso_by=group_iso_by, # 'gene_ids'
gene_names=gene_name_col, # 'gene_ids'
min_counts=min_counts,
min_bin_pct=min_bin_pct,
min_component_size=10 # remove disconnected tissue fragments if any
)
/Users/jysumac/Projects/SPLISOSM/src/splisosm/utils/preprocessing.py:832: UserWarning: Removed 100 spot(s) belonging to graph components with fewer than 10 member(s). 123558 spot(s) remain.
spatial_inputs = _filter_small_components(
CPU times: user 508 ms, sys: 103 ms, total: 611 ms
Wall time: 616 ms
%%time
model_np.test_spatial_variability(
method='hsic-ir',
null_configs={"n_probes": 60},
ratio_transformation='none',
print_progress=True,
)
SV [hsic-ir]: 100%|██████████| 116/116 [00:03<00:00, 33.01it/s]
CPU times: user 29.9 s, sys: 3.07 s, total: 33 s
Wall time: 5.26 s
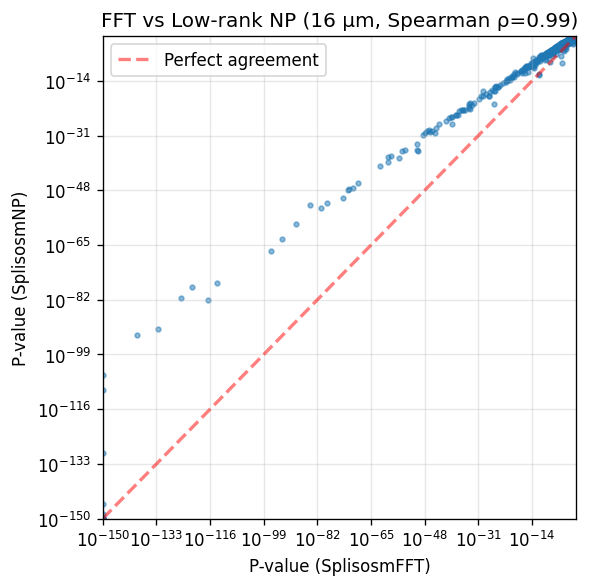
Compare p-values between SplisosmFFT and SplisosmNP:
# Extract results and merge
sv_np = model_np.get_formatted_test_results('sv')[['gene', 'pvalue']].copy()
sv_np = sv_np.rename(columns={'pvalue': 'pvalue_np'})
comparison = sv_res_16um[['gene', 'pvalue']].copy()
comparison = comparison.rename(columns={'pvalue': 'pvalue_fft'})
comparison = comparison.merge(sv_np, on='gene', how='inner')
corr, _ = spearmanr(comparison['pvalue_fft'], comparison['pvalue_np'])
print(f'Genes tested in both methods: {len(comparison)}')
print(f'== Significant in SplisosmFFT (FDR < 0.01): {(comparison["pvalue_fft"] < 0.01).sum()}')
print(f'== Significant in SplisosmNP (FDR < 0.01): {(comparison["pvalue_np"] < 0.01).sum()}')
print(f'== P-value correlation (Spearman rho): {corr:.4f}')
Genes tested in both methods: 1558
== Significant in SplisosmFFT (FDR < 0.01): 790
== Significant in SplisosmNP (FDR < 0.01): 538
== P-value correlation (Spearman rho): 0.9903
The two approaches yield almost identical rankings. SplisosmFFT shows slightly smaller p-values for top genes due to zero-padding that increases sample size (n=123,658 before vs n=175,561 after rasterization).
# Scatter plot comparison
fig, ax = plt.subplots(figsize=(5, 5))
x = comparison['pvalue_fft'].to_numpy()
y = comparison['pvalue_np'].to_numpy()
ax.scatter(x + 1e-150, y + 1e-150, s=8, alpha=0.5)
ax.set_xscale('log')
ax.set_yscale('log')
ax.set_xlabel('P-value (SplisosmFFT)')
ax.set_ylabel('P-value (SplisosmNP)')
ax.set_title(f'FFT vs Low-rank NP (16 µm, Spearman ρ={corr:.2f})')
ax.grid(True, alpha=0.3)
# Add diagonal reference line
lims = [1e-150, 1.0]
ax.plot(lims, lims, 'r--', alpha=0.5, label='Perfect agreement', linewidth=2)
ax.legend()
ax.set_xlim(lims)
ax.set_ylim(lims)
plt.tight_layout()
plt.show()
For reproducibility#
import sys
from datetime import date
import splisosm
print("Last updated:", date.today())
print("Python:", sys.version.split()[0])
print("splisosm:", getattr(splisosm, "__version__", "unknown"))
Last updated: 2026-05-03
Python: 3.12.13
splisosm: 1.2.0rc1